How to implement a scalable real-time synchronization solution for any file, folder or app size, over any network infrastructure, if you can’t or won’t use the cloud.
Introduction
As the world becomes more distributed, the workflow between teams is increasingly complex. A common scenario is of several teams working from different locations, that all need fast and reliable access to documents and data, and need to share their work with other teams. The general market trend is to put everything in the cloud, however, for many companies, this is not the answer. Cloud usage may be limited because of regulation, the big size of the files and the slow speed of sharing. Cloud can get expensive, which could be a limiting factor as well.
Many companies are looking for a solution that will allow them to place local servers in different locations, with the ability to synchronize data fast and reliably between them. This way the data stays inside the company to meet regulations, access to the data is fast, since data distributed over WAN only once and then accessed locally, it has a predictable price, and it can be easily scaled and extended.
Another trend is applications that spawn across several servers. While previously you might have had a single server for your application, current demand means you need more than one server to run your application, and those servers can be geographically distributed. Keeping your application and application data synchronized access several (sometimes hundred servers) is important to provide a consistent user experience for your business.
In this blog, we’ll look at the most common use cases and requirements, and compare different approaches to keeping files, folders and servers synchronized across different locations.
Most common use cases
- Applications, software builds or VMware images distribution:
One of the most popular use cases that we see is the distribution of the software builds, applications such as docker or VMware images to remote offices or a group of the servers. Once you have a master image that you want to have replicated to several servers, you need to build a reliable system to deliver it to a destination. You need to guarantee the delivery happened, and a method for automating the process over an API. You also need to solve the challenge of effective data distribution – making sure your central server is not overloaded & delaying the data delivery. - Distributed team collaboration:
Another popular real-time synchronization use case is creating a system that allows distributed teams to work on the same projects and making sure they get access to the latest files. The speed of file update propagation is crucial here. You don’t want one team working on an old file, while another office already has a new version. The speed of file preparation includes not only the time it takes to transfer the file but also time to detect that file is changed. You want to have a system that is reliable, will recover from errors and make sure that the latest file is always available to all teams. - Distributing media files:
The media file synchronization and distribution case is similar to the collaboration use case, but files are significantly bigger. Delivering big files requires additional steps to make it fast. You want to overcome any connection interruptions without a need to retransmit files. You want to transfer only the changed parts of the files, instead of sending the whole file. You may want to limit bandwidth for the sync job, so it won’t occupy all bandwidth available. Server synchronization priority is also important here, you may have several synchronization jobs and some data may need to travel faster. - Backing up data from remote offices:
Last but not least, is the need to backup data from remote offices to a central server in real-time. The organization must have all documents, data, and information produced in remote offices backed up fast and reliably to the central location. The system needs to guarantee data delivery, be able to overcome networking and system failures, properly survive a restart of the machines. It also has to keep synchronization going under networking condition changes like a change of IP address. One of the important aspects of the system must be remote administration, so there is no need for IT presence at the remote office.
What are your requirements?
Let’s go over the key features for designing a real-time synchronization and distribution system. You may need just several of the features right now, but you should still understand all possible options in order to expand your sync solution in the future.
Real-time
Well, clearly the real-time aspect is the most important one in these scenarios, that’s why you’re reading this article in the first place. Your system must detect changes in data in real-time and start transfer immediately. This significantly reduces the number of cases of two teams working on different versions of the data. The system you implement has to leverage specific OS interfaces like Linux inotify to detect changes on the fly and immediately start synchronization.

Fast
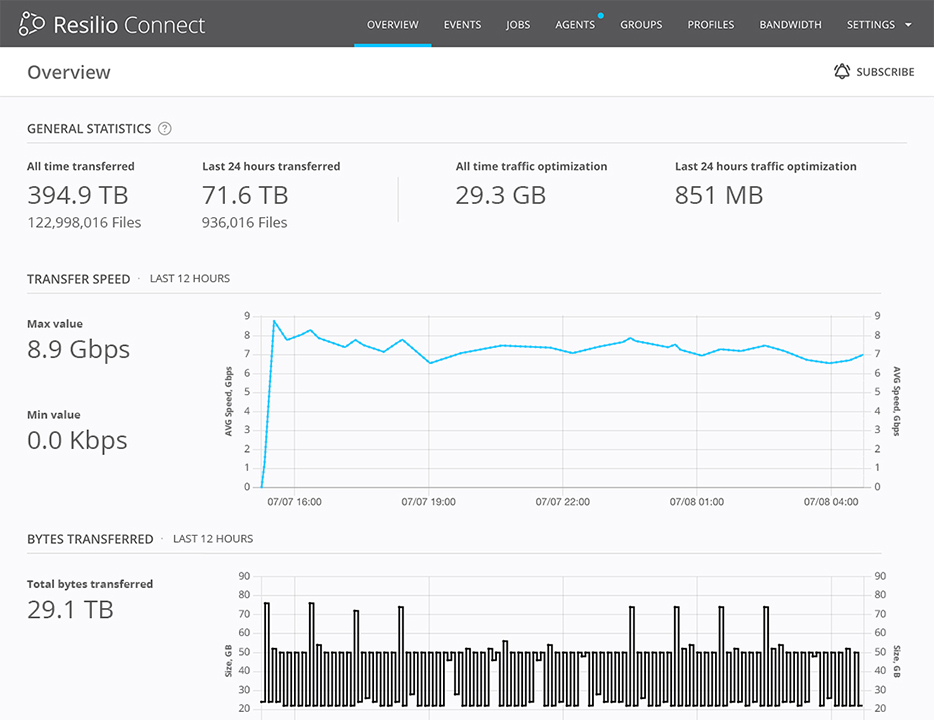
Data transfer speed is crucial for keeping offices synchronized. Your solution has to include a set of data transfer optimizations to guarantee the fastest possible delivery speed. You need a peer-to-peer, so servers can distribute data independently in a swarm and not overload the central server networking and HDD. You need delta deduplication (think rsync), so only changed chunks are transferred. The compression of the data can reduce the size of data that is delivered over the network, so it increases the speed of synchronization. And of course, your system needs to have a WAN-optimized protocol that ensures the fast speeds over connections with high RTT (Round Trip Time) and packet loss. This is important for keeping servers in sync over long geographic distances.
Big files
The system must be able to handle big files of any size effectively, even TB sized files. You should be able to avoid retransmission in case of network or system errors. The system should be able to detect changes in big files, so only the changes are distributed. The system also needs to have optimized disk IO and know how to properly work with big files to reduce the hard drive load.
Millions of files
In some cases, a server will hold millions of files, and you need to make sure all those millions are identical across several locations. The system needs to detect changes to the millions of files in any location in real-time. Let’s assume you have three locations, detecting which site changed the file and distributing it to the other locations in real-time is not trivial. Your system needs to ensure if two sites started changing the same file all the sites will have a consistent view when synchronization is done. Another important aspect is that the system needs to properly deal with the cases when server #1 is offline and there were a lot of changes on server #2 and #3. When server #1 comes back online, the list of changes both on all servers needs to properly combine and synchronize.
Versioning
In a distributed environment there are always cases when two people work on the same file at once. The system needs to ensure there is proper versioning in place, so file conflicts can be resolved and no data is lost.
Scalability
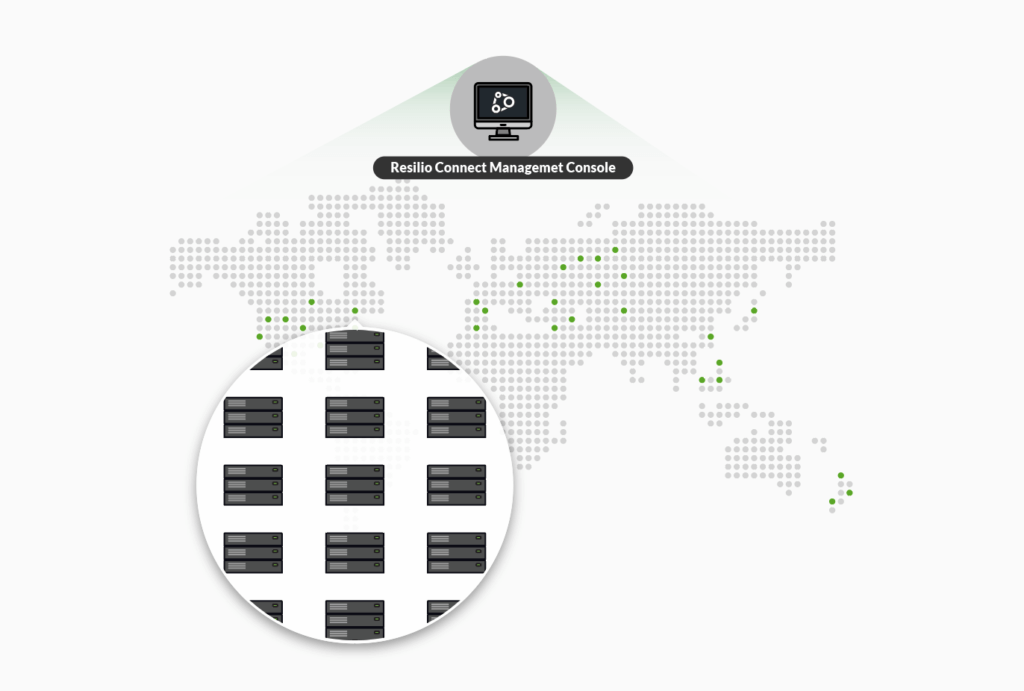
How are you going to scale your real-time synchronization solution? Technically it is quite easy to keep two servers in sync, but as soon as you drop an additional server in the mix, it becomes more complex. The current market approach is to create one master copy of the data, synchronize all the changes from remote servers to the master copy, and then distribute an updated master copy to remote servers. As you can see adding an additional server to the equation increases the time to synchronize, and is very sensitive to connectivity and system errors. You want your system to utilize peer-to-peer so that there is no master copy and each server can talk to other servers and contribute to synchronization independent of its state. Your system must keep complexity the same whether synchronizing 2 or 1,000 servers.
Overcome errors
An extremely important feature for data synchronization in real-time is error detection and recovery. Errors will happen, unfortunately, but your sync solution should recover fast and continue operating without human intervention. Common failures you should be able to overcome automatically are system failures, HDD lack of space, changed IP addresses, software failures, reboots, etc. Once the offline server becomes online, it should be able to understand what changes were missed and effectively bring the server back to sync with other servers.
Centrally managed
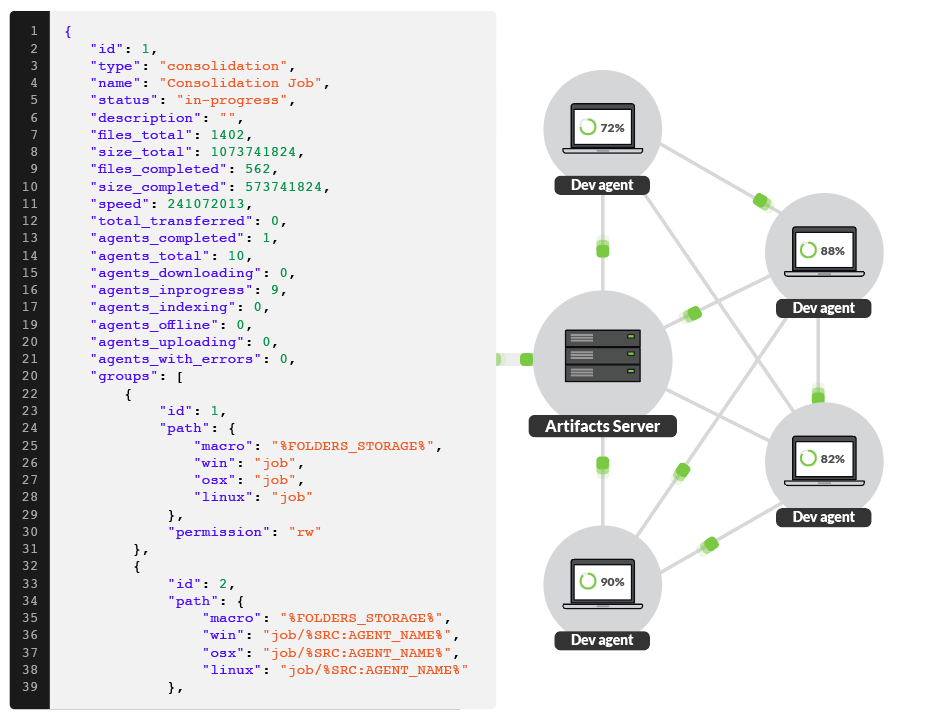
Managing synchronization processes across the servers requires central management. A system that requires scripts, rules or configurations updated on all servers won’t work at scale. You need to control synchronization for all servers from a central location that gives you a complete view of the progress, allows you to change synchronization parameters and add or remove synchronization jobs on the fly.
WAN optimization
In many cases, your servers will be located in locations far apart geographically. The distance between servers matters because of the TCP/IP protocol design. When the time to transfer a packet increases, the speed of the TCP/IP protocol drops. Additionally, long distances increase the chance of a lost IP packet, since it travels through more routers and can experience more failures or congestions in any of the hardware units. The TCP/IP treats packet drops as congestion in the network and reduces the speed of the transfer in response. If you utilize WAN optimization, you can ensure that time to transfer and packet drops over long distances are properly treated and speed is not reduced in response.
ACL synchronization
Synchronized files on the server must have the ability to synchronize file permissions (ACL) as well as user and group information. The destination file must have the same permissions as a file on the original server.
Priority, scheduler, and bandwidth allocation
You want your system to have the ability to control your synchronization processes. Not all jobs are equally important, and you have to be able to define different priorities so your more important data propagates faster. In some networks, you will need to specify bandwidth for the synchronization job, so it doesn’t overload the network and affect the day to day operation of your office. In some cases, you don’t need real-time synchronization, but want to ensure that servers are synchronized after some period of time.
Security
Security in a sync solution has several components. Data must be encrypted during transit. Additionally, it needs to ensure that only authenticated servers connect and receive updates and that only authorized servers can change the data. You should also be able to securely remove the server from synchronization at any time.
API
The server synchronization as a process is typically a part of a more complex workflow. The API should allow you to create, stop and pause synchronization jobs, modify synchronization parameters, get synchronization status reports, report errors. You need a centrally based API, so you could monitor and manipulate servers by contacting one access point, without the need to remotely access all servers.
What’s the right solution?
Now that we’ve reviewed all the features needed in a reliable real-time synchronization system, let’s help you choose the right one for you.
Of course, we created Resilio Connect for these challenges, and have built-in the full set of features described above, so you get real-time synchronization software that is reliable at any scale.
Here’s a comparison of the most common synchronization tools and how they stack up against these requirements:
| rsync | DFSR | robocopy | Aspera | Resilio Connect | |
|---|---|---|---|---|---|
| Peer-to-peer | – | – | – | – | ✔ |
| Real-time | – | ✔ | – | – | ✔ |
| Diff deduplication | ✔ | ✔ | – | ✔ | ✔ |
| Error recovery | – | – | – | – | ✔ |
| 1M+ files | – | ✔ | – | ✔ | ✔ |
| 1TB files | ✔ | ✔ | – | ✔ | ✔ |
| Versioning | – | – | – | – | ✔ |
| Centrally managed | – | ✔ | – | ✔ | ✔ |
| Central API | – | ✔ | – | ✔ | ✔ |
| ACL synchronization | ✔ | ✔ | ✔ | ✔ | ✔ |
| Priority | – | – | – | ✔ | ✔ |
| Bandwidth allocation | ✔ | ✔ | – | ✔ | ✔ |
| Scalability | – | – | – | – | ✔ |
Would you like to learn more about Resilio Connect? Or would you prefer to see Resilio Connect in action by scheduling a demo or starting a free trial?