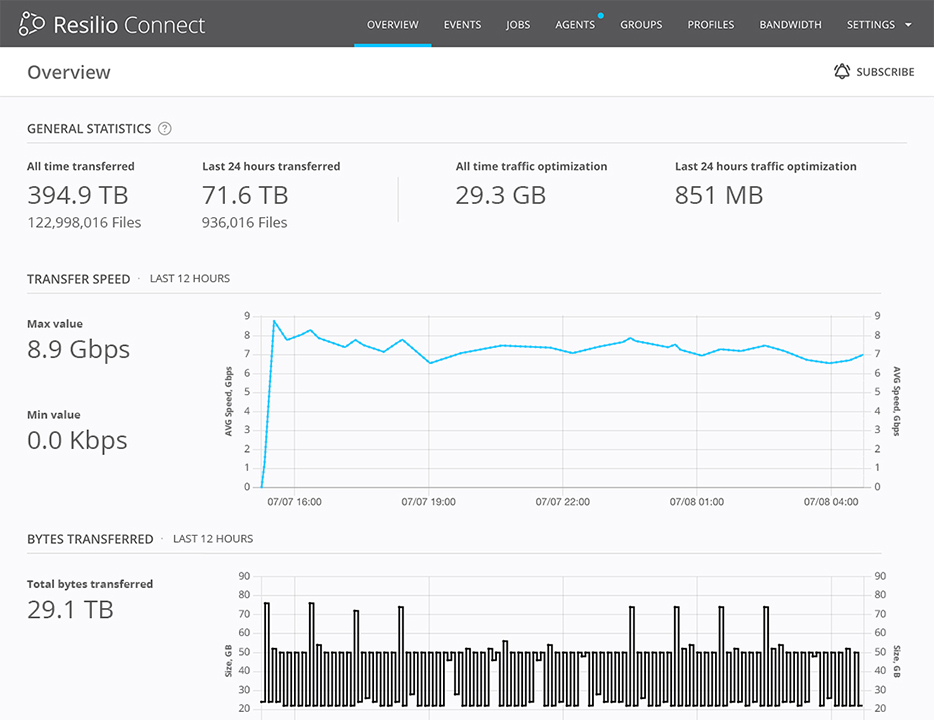
While it sounds seemingly easy, bidirectional synchronization (or two-way sync) is actually an advanced file replication capability. Few vendors offer it–and those that do have severe limitations.
This article addresses what to look for in a file-based bidirectional sync solution. (FYI: Resilio does not address bidirectional synchronization or replication of databases such as SQL, postgreSQL, mySQL; nor CRM or ERP databases.)
In this blog we’ll cover two-way sync use cases and what to look for when evaluating a solution for bidirectional sync. Finally, we’ll cover a few best practices for Resilio Connect.
If you want to skip the blog and see a live bidirectional sync demonstration, please get in touch with us!
Bidirectional Sync Use Cases
The business needs and use cases for bidirectional synchronization are many: local and global file collaboration, data protection across sites with built in high availability, disaster recovery, server sync, storage sync, VDI profile sync, and so forth; the list of use cases goes on and on. Yet finding a highly reliable, efficient, fast, and scalable implementation of bidirectional sync (that’s also easy to use) is no easy task.
Many enterprise customers simply need bidirectional sync for collaboration across sites that also provides high availability and ideally disaster recovery. For example, consider a simple two site configuration (Site A and Site B), where both sites host multiple endpoints. The customer would like all of their file data to be current and readily available.
If a user in Site A changes a file, it synchronizes with all other peers in Site A as well as Site B; and vice versa. Resilio Connect makes two-way sync fast and easy across both sites. Any user can change any file stored on either site–and they will be kept in sync. Sounds simple but that’s where Resilio comes in, enabling this across multiple endpoints (mobile devices, desktops, servers, storage) and sites.
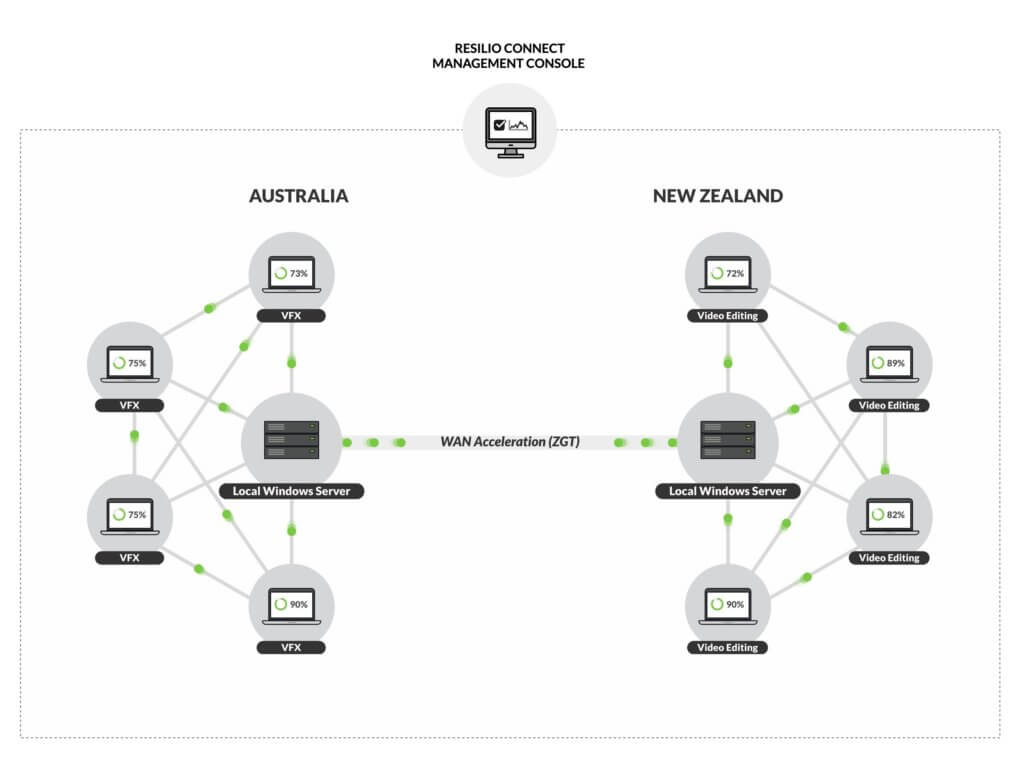
As an added bonus, using Resilio the agents can run on different operating systems (Widows, Linux, macOS, and so forth). And if there’s latency across sites (most WANs have 100+ ms latency), Resilio overcomes the latency through its UDP-based WAN optimization, Zero Gravity Transport, for only the WAN connection between the sites. Endpoints within each site can use TCP.
In this basic multi-site setup, there is no single point of failure, active-active high availability is provided across all servers and both sites, and multiple users can collaborate in real-time on the same files. And diaster recovery (DR) is enabled as well: recovery can be extremely fast and data loss can be minimized to sub-5-second recovery points.
One-way Synchronization
Most contemporary storage replication and file sync tools do not support two-way sync. For example, rsync, Isilon SyncIQ, and NetApp SnapMirror only support one-way synchronization. In Isilon SyncIQ, for example, you can set policies to have one-way sync going in two directions, but it’s not true bidirectional sync. In NetApp SnapMirror, you can have a “synchronous” mirror, but it’s a one-way sync, usually from a production source to a disaster recovery target. I can’t think of a single storage vendor that provides true N-way or bidirectional sync. Most storage-based approaches replicate or sync files off of a snapshot taken in one location, and replicate the changes to a second location, one-way.
Bidirectional Sync Challenges
Data and storage sprawl are products of data growth. So, too, is cloud sprawl: with more file-based data moving into file and object stores, those files still need to be managed and kept current with other data stores.
People are also widely distributed across locations and want to use their data on a variety of devices in a variety of places. So the complexity of keeping all of this data “in sync” and current and available across all of these heterogeneous devices and global locations becomes paramount. But how?
One way of dealing with data sprawl is to partition the data sets across multiple storage systems (each running separate file systems) and then provide some level of abstraction, or data mapping, across the systems, using a distributed file system or global namespace or something like Hammerspace. While these approaches may simplify access, the problem of keeping all of the files synchronized across all of these storage silos persists. More challenging still is keeping all files current while users and applications are actively changing files across multiple file systems, in parallel.
The Bidirectional Sync Landscape
At Resilio, we think of bidirectional sync and replication like a reliable utility; where it just works in the background across as many devices and locations as needed. Resilio provides a highly reliable and scalable way of synchronizing files, folders, and directories across nearly any number of locations and endpoints—in any direction. This can be one-way or two-way sync, one-to-many, many-to-one, or many-to-many. Transparent selective sync enables users to browse and selectively download files as needed, on-demand.
Conventional Bidirectional Sync Limitations
Conventional replication and file synchronization tools simply can’t keep up with the scale of data movement and processing required to keep all files consistently synchronized across multiple physical locations. Storage replication products replicate one-way, which may be sufficient for basic recovery and data protection—but fail keeping files current across multiple file systems.
Conventional file sync tools that do support “two-way sync” have considerable limitations, especially when used for enterprise use cases. Tools like Unison, Microsoft DFSR, Goodsync, and Aspera Sync all support bidirectional sync but are all based on a point-to-point architecture.
Issues with conventional approaches to bidirectional sync include:
- Serialized data transfer between at most two (2) systems — which limits performance, availability, and suitability for enterprise organizations.
- Hub-and-spoke forces all changes to flow through a hub, which is a performance bottleneck and single point of single point of failure.
- Lack of flexibility to include more than 2 endpoints in the bidirectional synchronization process.
- Single point of failure: If one computer goes down during the synchronization process, the entire job fails.
DFSR, for example, offers a limited bidirectional sync capability through a multi-master design; it’s slow, error-prone, and we’ve heard can cause data corruption. We highly recommend replacing DFSR with Resilio Connect.
Older tools like Unison do a good job for two-way synchronization between at most 2 computer systems, and for synchronizing the changes in a hub-and-spoke topology. Aspera Sync is similar to Unison in this regard, but does have WAN optimization. Yet when run in “bidirectional sync” mode, Aspera Sync is fraught with problems, including (like Unison) manual conflict resolution. The last thing anyone wants to be doing while collaborating is diagnosing and resolving file access and naming conflicts.
So why do most bidirectional sync tools have all of these limitations? They are due to:
- Point-to-point architectures: Bidirectional synchronization can only occur between at most 2 computers, or Replicas. The data source can be located on either system, but there can be only 2 data sources. Once the two systems are synchronized, then other systems can be synchronized in a follow-the-sun or hub-and-spoke topologies.
- Hub-and-spoke is a product of point-to-point. All changes must go through the hub, which delays the sync from spoke to spoke. The hub is a bottleneck for performance and delays the “two-way sync” to reaching each spoke. The hub is also a single point of failure.
- Poor scalability: Unison, Goodsync, DFSR, Aspera Sync, and other client-server approaches do not scale. You can “scale up” by using multithreading / pthreads to use more CPU, memory, and possibly storage IO within each endpoint–but you can not scale out.
- Multi-master, client-server architectures fail at scale. In Microsoft DFSR, for example, two-way sync is tricky to configure, error-prone, and in the worst case scenario may corrupt data. DFSR also performs poorly, unpredictably, and does not scale when replicating to multiple sites.
- Limitations with file sizes and numbers of files: Conventional bidirectional synchronization is limited to smaller files and fewer files on each computer system. Unison, DFSR, and other conventional tools struggle with two-way synchronization of large files and larger numbers of files. Moreover, they can not sync files in a reliable way across unreliable network conditions.
- Not real-time and/or lack real-time bidirectional sync. Some implementations have to re-sync the entire file when a change is made. Others, like DFSR, support partial file replication—but bottleneck and delay the file change replication in a backlog (or queue) of changes. Others like Goodsync can only sync in real-time between 2 endpoints.
- File naming and access conflicts: Conflict resolution in conventional bidirectional synchronization is highly problematic and error-prone, often resulting in manual troubleshooting and manual conflict resolution. For example, tools, like Unison and Apsera Sync, offer ways to manually resolve conflicts, which is intrusive and potentially error-prone. In Unison, for example, the end user is given an opportunity to view and choose actions for conflicting updates.
- Data corruption or data loss: At their worst, these traditional approaches to bidirectional synchronization do not preserve data integrity and may cause data loss.
Unfortunately, these conventional storage replication and data synchronization tools don’t support reliable, highly available, real-time, nor scalable two-way sync. Thus, customers end-up with higher levels of complexity (e.g., conflicts), poor performance, and potentially data corruption.
What to Look for in Bidirectional Synchronization Solutions
In polling storage experts, enterprise customers, and the technical salesforce, an enterprise-class bidirectional sync solution should provide:
- Data integrity: File integrity should always be preserved end-to-end during the sync process; there should never be data corruption—no matter what.
- Bulletproof reliability and availability: If a failure occurs during the bidirectional synchronization job, the job should continue undisrupted; or at the very least resume where the job failed. There should never be a single point of failure.
- Native Security: Authorization authentication, and encryption should be provided natively and end-to-end—without relying on 3rd-party security services.
- Ease of use and central management: The two-way sync process should offer automation or just work in the background. Users and IT administrators should not have to drop what they are doing to investigate and arbitrate file conflicts, be it file naming or access-related conflicts. Moreover, there should be some form of central control, where IT administrators can monitor and track jobs.
- Automation: All aspects of bidirectional synchronization should “just work” behind the scenes. There should be extensibility through scripting or APIs for job control, tracking, and monitoring. Webhooks or other management infrastructure should enable notifications and other ways to keep track of the sync jobs.
- Scalability for larger data sets: As file sizes and file system sizes continue to grow, the directional sync capabilities of the replication system should support synchronizing large files and large numbers of files, across a variety of networks.
- Seamless SaaS-like endpoint scalability: Larger enterprises have moved well beyond the need of transferring and synchronizing files between only 2 computers. Enterprises need two-way sync and multi-directional synchronization across many endpoints, concurrently; in some cases hundreds or thousands of endpoints. It should be easy and non-disruptive to add endpoints and scale the job over time.
- Speed and performance: When a change occurs, the file changes should be instantly propagated at full-speed, based on what the customer needs. should be no delay and performance be at allocated speeds.
- Efficiency: This relates to replication architecture and network efficiency. When a chunk of data changes, only the changed portion, or delta, should be synchronized; and full utilization of the network should be obtained, no matter the type or bandwidth.
- Flexibility: You should be able to use your choice of OS, servers, storage, and IT infrastructure or cloud — and it should be easy to adapt the configuration to evolving business needs and business processes.
Highly Reliable Bidirectional Synchronization
Resilio Connect offers highly reliable bidirectional synchronization across multiple systems located anywhere. Resilio’s peer-to-peer synchronization model enables multiple endpoints to participate in two-way data synchronization. Resilio offers complete automation and tremendous flexibility in configuring site-to-site two-way synchronization using multiple peers.
The benefits of Resilio include scale-out performance, increased availability, and no single point of failure. Other benefits include real-time bidirectional synchronization for efficiency (only the delta is replicated and synchronized), WAN optimization, and scalability to address large files (there are no file size limits) and file systems containing many millions of files. Scripting and a well documented API set are also provided. The advantage of using Resilio Connect are numerous:
- Unmatched Reliability: Files are always protected end-to-end during the synchronization process and there is no single point of failure.
- Flexibility: Bidirectional synchronization is supported across as many systems (desktops, mobile devices, servers, and storage) as you need—and in real-time.
- Speed: Resilio Connect is 10-100x faster than conventional tools like Unison and Apsera Sync—as well as other peer-to-peer tools like Resilio Sync.
- Real-time, low latency automation: Resilio Connect replicates and synchronizes the changed portion of the file instantly and within sub-5-second end-to-end latency.
- Multi-directional sync: From a directional sync perspective, this can be one-way, two-way, one-to-many, many-to-one, or many-to-many (full mesh). Resilio Connect provides this flexibility natively and efficiently. Resilio Connect’s implementation of bidirectional synchronization and multi-directional synchronization scales to 250+ million files per job across many thousands of endpoints. Up to 30K endpoints can be managed with each management console and scales to 150K+ endpoints per cluster.
- Unparalleled performance at scale. Using Resilio Connect, you can sync files across many many thousands of endpoints in fixed and predictable time frames; synchronizing a file across thousands of endpoints takes about the same synchronizing files between 2 endpoints.
How It Works
Resilio is based on a peer-to-peer architecture that splits up files into chunks and efficiently distributes and replicates files across multiple peers in parallel. This distributed architecture both outperforms traditional point-to-point solutions and offers unmatched scalability, reliability, and availability.
This both speeds up the bidirectional synchronization process (simply add more endpoints and increase bandwidth to increase performance) and extends the capability to everyone in the organization, irrespective of their locations.
Resilio has also optimized the entire synchronization process end-to-end, to support synchronization of large files, many millions of files, and synchronization across large numbers of endpoints.
If you want to learn more about the differences between P2P and point-to-point (also known as client-server), check out the overview of P2P on Resilio.
Managing Conflicts
One of the questions that comes up around bidirectional sync has to do with conflict resolution.
At its core, Resilio Connect ensures data integrity and reliability of the entire sync process. Users simply work with files the way they normally would on their operating system of choice and don’t need to worry about what’s happening under the hood. As part of that, users and administrators should not need to stop what they are doing to manage conflicts during the synchronization process.
While conflicts rarely happen in the Resilio model, there are some best practices for minimizing conflicts and automating the resolution during the sync process. First, it’s easy to set certain peers as “priority” peers in case there is a conflict. That way the priority peer will always win ownership. Second, it’s easy to manage file naming conflicts. In the Resilio Connect agent profile, there’s an option to Resolve filename system conflicts, which can be enabled. If there is a file naming conflict, the older files are stored in an Archive folder, easily accessible to end users.
Finally, Resilio has the ability to set some agents within a synchronization job to read-only. In situations where you want certain agents not to sync their changes, Resilio makes it easy to set this up.
The bottom line is that IT gains tremendous control over how the synchronization job works. This makes bidirectional synchronization extremely reliable and easy to manage.
Resilio Connect vs Traditional Bidirectional Sync
Here’s how Resilio Connect stacks up to point-to-point bidirectional sync solutions:
| Capability | Resilio Connect | Point-to-Point |
| Support more than 2 endpoints (replicas) | + | – |
| Sync large file systems with 250+ million files | + | – |
| Unlimited file sizes | + | – |
| Real-time file sync for more than 2 endpoints | + | – |
| Two-way sync / bidirectional sync | + | + |
| One-to-many sync in parallel | + | – |
| Many-to-one sync in parallel | + | – |
| Many-to-many sync in parallel | + | – |
| Compression | + | + |
| Dynamic IP support | + | – |
| Encryption | + | – |
| WAN optimization | + | – |
| NAT traversal | + | – |
| Cross-platform | + | + |
| Proxy Server | + | – |
| S3 cloud storage support | + | – |
| Large directory support | + | – |
| Active-active high availability / no SPOF | + | – |
| Automated, policy-based conflict resolution | + | – |
Feature Comparison Summary
Summary
While conventional bidirectional sync tools do a solid job with basic 2-way file synchronization across at most 2 computers, Resilio scales to many endpoints and locations—keeping all of your files current and accessible to users and applications—globally, across as many places as needed.
Moreover, Resilio supports unlimited file sizes (files can be of any size and type) and synchronization jobs may contain 250+ million files per job.
Resilio gives you peace of mind and saves countless hours of management time. Files are resilient to failures. Resilio’s peer-to-peer architecture ensures there is no single point of failure (SPOF). File backup & sync for Disaster Recovery (DR) and upgrades are easier and faster. Files are continuously protected and highly available across as many servers as needed. Moreover, you can accelerate performance on-demand. Simply add endpoints and increase bandwidth to increase performance.
The Resilio Connect solution is also cross platform. Servers can be of any type. Physical, virtual, containerized. Running Windows, Linux, macOS, or FreeBSD—and a variety of NAS systems. Use storage and networks you already own. Resilio Connect also supports any S3-compatible cloud storage.
We’d love to show a demo of Resilio Connect and discuss your environment. Or feel free to schedule a Resilio Connect demo or start a free trial to see how much faster and easier bidirectional synchronization could be for you.